RAG là gì? Retrieval-Augmented Generation hoạt động như thế nào và khác gì Fine-tuning?
RAG kết hợp truy xuất dữ liệu thời gian thực với LLM để giảm hallucination, tăng độ tin cậy. Tìm hiểu cách RAG hoạt động, so sánh với Fine-tuning và ứng dụng thực tế.
RAG là gì? Retrieval-Augmented Generation hoạt động như thế nào và khác gì Fine-tuning?
Trong lĩnh vực trí tuệ nhân tạo, Retrieval-Augmented Generation (RAG) đang được xem là một trong những giải pháp hiệu quả nhất để tạo ra nội dung chính xác, có căn cứ và dễ kiểm chứng.
Thay vì chỉ dựa vào dữ liệu huấn luyện sẵn như các mô hình ngôn ngữ truyền thống, RAG kết hợp truy xuất dữ liệu thời gian thực với sức mạnh của mô hình ngôn ngữ lớn (LLM).

Nhờ đó, RAG giúp:
- ✅ Giảm hiện tượng hallucination (AI bịa thông tin)
- ✅ Cải thiện độ tin cậy của câu trả lời
- ✅ Mở ra nhiều ứng dụng thực tiễn trong doanh nghiệp, giáo dục, y tế và tài chính
Vậy RAG là gì? Cơ chế hoạt động ra sao và khác gì so với Fine-tuning truyền thống?
Retrieval-Augmented Generation (RAG) là gì?
Retrieval-Augmented Generation (RAG) là một phương pháp trong trí tuệ nhân tạo kết hợp hai thành phần cốt lõi:
1. Mô hình ngôn ngữ lớn (Large Language Model – LLM)
LLM là nền tảng để:
- Hiểu ngữ cảnh câu hỏi
- Tổng hợp thông tin
- Sinh ra câu trả lời tự nhiên
Ví dụ LLM phổ biến:
- GPT-4, GPT-3.5 (OpenAI)
- Claude (Anthropic)
- LLaMA (Meta)
- Gemini (Google)
2. Cơ chế truy xuất dữ liệu từ kho tri thức bên ngoài
Retrieval system giúp:
- Tìm kiếm thông tin liên quan
- Truy xuất từ nhiều nguồn
- Cung cấp context cho LLM
Nguồn dữ liệu có thể là:
- 📄 Tài liệu nội bộ công ty
- 🗄️ Database
- 🌐 Website
- 📚 PDF, Word, Excel
- 📊 Knowledge base
Định nghĩa từ các tổ chức uy tín
Theo IBM:
RAG được thiết kế để khắc phục hạn chế lớn nhất của LLM truyền thống: chỉ dựa vào dữ liệu huấn luyện sẵn, dẫn đến việc mô hình có thể tạo ra thông tin lỗi thời hoặc không chính xác.
Theo Amazon:
RAG cho phép các mô hình ngôn ngữ lớn truy cập thông tin từ nguồn dữ liệu bên ngoài mà không cần huấn luyện lại mô hình.
RAG giải quyết vấn đề gì?
1. Giảm hiện tượng hallucination
Vấn đề với LLM thuần:
User: "Doanh thu Q4 2024 của công ty chúng ta là bao nhiêu?"
LLM thuần: "Doanh thu Q4 2024 là 50 triệu USD"
(Bịa số liệu vì không có dữ liệu thực)
Với RAG:
User: "Doanh thu Q4 2024 của công ty chúng ta là bao nhiêu?"
RAG:
1. Truy xuất từ báo cáo tài chính Q4 2024
2. Tìm thấy: "Doanh thu Q4 2024: 45.3 triệu USD"
3. Trả lời: "Theo báo cáo tài chính Q4 2024,
doanh thu là 45.3 triệu USD"
2. Cung cấp câu trả lời có nguồn dẫn rõ ràng
Lợi ích:
- ✅ Người dùng có thể verify thông tin
- ✅ Tăng độ tin cậy
- ✅ Minh bạch nguồn gốc thông tin
Ví dụ:
Câu trả lời: "Theo chính sách nhân sự trang 15,
nhân viên được hưởng 15 ngày phép năm."
Nguồn: [Chính sách nhân sự 2024.pdf, trang 15]
3. Cho phép AI cập nhật kiến thức liên tục

Khi người dùng đặt câu hỏi:
- Hệ thống RAG truy xuất thông tin liên quan từ kho dữ liệu
- Đưa dữ liệu này vào LLM
- LLM tổng hợp và sinh ra câu trả lời cuối cùng
Lợi ích:
- ✅ Không cần huấn luyện lại mô hình
- ✅ Chỉ cần cập nhật kho dữ liệu
- ✅ Thông tin luôn mới nhất
Lợi ích của Retrieval-Augmented Generation (RAG)
RAG mang lại nhiều lợi ích nổi bật cho các hệ thống AI hiện đại:
1. Nâng cao độ chính xác và độ tin cậy
Nhờ sử dụng dữ liệu thực tế từ nguồn bên ngoài, RAG giúp AI đưa ra câu trả lời có căn cứ, hạn chế tối đa việc "bịa đặt thông tin".
So sánh độ chính xác:
| Metric | LLM thuần | RAG | | ---------------------- | --------- | ------ | | Accuracy | 60-70% | 85-95% | | Hallucination rate | 20-30% | 3-8% | | Source citation | Không có | Có | | Verifiable | Khó | Dễ |
Ví dụ thực tế:
Câu hỏi: "Chính sách bảo hành sản phẩm X là gì?"
LLM thuần: "Bảo hành 12 tháng" (có thể sai)
RAG: "Theo tài liệu bảo hành, sản phẩm X được
bảo hành 24 tháng với điều kiện..."
[Nguồn: Chính sách bảo hành 2024.pdf]
2. Cập nhật thông tin liên tục
RAG không bị giới hạn bởi dữ liệu huấn luyện cũ.

Workflow cập nhật:
1. Có thông tin mới (sản phẩm mới, chính sách mới)
2. Upload vào knowledge base
3. RAG tự động sử dụng thông tin mới
4. Không cần retrain model
Phù hợp với các lĩnh vực biến động nhanh:
- 💻 Công nghệ: Cập nhật tính năng mới
- 💰 Tài chính: Thay đổi quy định, giá cả
- 🏥 Y tế: Nghiên cứu mới, thuốc mới
- 📰 Tin tức: Sự kiện mới nhất
3. Tối ưu chi phí triển khai
So sánh chi phí:
| | Fine-tuning | RAG | | ------------------ | ----------------- | ------------ | | Initial setup | $5,000-50,000 | $1,000-5,000 | | Update cost | $2,000-10,000/lần | $0-100/lần | | GPU needed | Nhiều | Ít/Không cần | | Time to update | 1-2 tuần | Vài phút | | Maintenance | Cao | Thấp |
Lợi ích:
- ✅ Chỉ cần cập nhật nguồn dữ liệu truy xuất
- ✅ Không cần GPU mạnh để retrain
- ✅ Tiết kiệm chi phí tính toán
- ✅ Giảm thời gian phát triển
4. Cải thiện trải nghiệm người dùng
Câu trả lời do RAG tạo ra thường:
- ✅ Chi tiết: Đầy đủ thông tin cần thiết
- ✅ Đúng ngữ cảnh: Phù hợp với câu hỏi
- ✅ Có dẫn chứng: Trích nguồn rõ ràng
- ✅ Đáng tin cậy: Dựa trên dữ liệu thực
Kết quả:
User satisfaction: 75% → 90%
Trust score: 60% → 85%
Repeat usage: 40% → 70%
RAG hoạt động như thế nào?
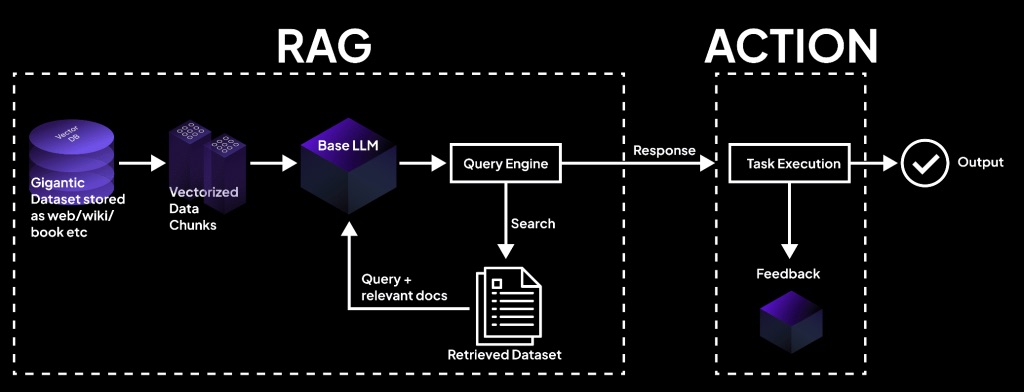
Quy trình hoạt động của RAG gồm hai bước chính:
Bước 1: Retrieval – Truy xuất thông tin
Hệ thống sử dụng tìm kiếm ngữ nghĩa (semantic search) để xác định các tài liệu, đoạn văn hoặc dữ liệu liên quan nhất đến câu hỏi của người dùng từ kho tri thức.
Quy trình chi tiết:
1. Chuyển đổi câu hỏi thành vector (embedding)
# Ví dụ
question = "Chính sách nghỉ phép của công ty?"
question_vector = embedding_model.encode(question)
# Output: [0.23, -0.45, 0.67, ...] (768 dimensions)
2. Tìm kiếm trong vector database
# Tìm top-k documents tương tự nhất
similar_docs = vector_db.search(
query_vector=question_vector,
top_k=5
)
3. Lấy nội dung các documents liên quan
Top 5 documents:
1. "Chính sách nhân sự 2024.pdf" - Similarity: 0.92
2. "Quy định nghỉ phép.docx" - Similarity: 0.87
3. "Employee handbook.pdf" - Similarity: 0.81
...
Công nghệ sử dụng:
- Embedding models: OpenAI embeddings, Sentence-BERT
- Vector databases: Pinecone, Weaviate, ChromaDB, FAISS
- Search algorithms: Cosine similarity, Approximate Nearest Neighbor
Bước 2: Generation – Sinh câu trả lời
Những thông tin đã truy xuất được đưa vào mô hình ngôn ngữ lớn (LLM). Dựa trên dữ liệu này kết hợp với kiến thức sẵn có, LLM sẽ tổng hợp và sinh ra câu trả lời hoàn chỉnh.
Prompt template:
Context:
{retrieved_documents}
Question: {user_question}
Instructions:
- Answer based on the context provided
- If information is not in context, say "I don't have that information"
- Cite sources when possible
Answer:
Ví dụ cụ thể:
Context:
"Theo chính sách nhân sự 2024, nhân viên full-time
được hưởng 15 ngày phép năm, tăng lên 18 ngày sau
3 năm làm việc."
Question: "Tôi được bao nhiêu ngày phép?"
Answer: "Theo chính sách nhân sự 2024, nhân viên
full-time được hưởng 15 ngày phép năm. Sau 3 năm
làm việc, số ngày phép sẽ tăng lên 18 ngày.
Nguồn: Chính sách nhân sự 2024, mục 3.2"
👉 Nhờ cơ chế này:
- ✅ RAG vừa đảm bảo tính cập nhật
- ✅ Vừa giữ được khả năng diễn đạt tự nhiên của LLM
Theo NVIDIA:
RAG giúp giảm đáng kể hiện tượng hallucination và đặc biệt phù hợp với các lĩnh vực yêu cầu độ chính xác cao như y tế, pháp lý và tài chính.
Sự khác biệt giữa RAG và Fine-tuning
Khi tìm hiểu RAG là gì, nhiều người thường so sánh RAG với Fine-tuning – phương pháp tinh chỉnh mô hình bằng cách huấn luyện thêm trên dữ liệu mới.
So sánh chi tiết RAG và Fine-tuning
| Tiêu chí | RAG | Fine-tuning | | --------------------- | ----------------------------- | ------------------------ | | Cách tiếp cận | Truy xuất dữ liệu ngoài + LLM | Huấn luyện lại mô hình | | Cập nhật tri thức | Dễ, chỉ cần cập nhật dữ liệu | Khó, phải huấn luyện lại | | Chi phí | Thấp hơn ($100-1,000) | Cao ($5,000-50,000) | | Thời gian setup | Vài giờ - vài ngày | 1-2 tuần | | Khả năng mở rộng | Linh hoạt, đa nguồn | Giới hạn bởi dataset | | Minh bạch | Có thể dẫn nguồn | Khó truy vết nguồn | | GPU cần | Ít hoặc không | Nhiều GPU mạnh | | Hallucination | Thấp (3-8%) | Trung bình (10-20%) | | Use case | Cập nhật thường xuyên | Behavior/style cố định |
Khi nào dùng RAG?
✅ RAG phù hợp khi:
- Cần cập nhật kiến thức thường xuyên
- Dữ liệu thay đổi nhanh
- Cần trích nguồn rõ ràng
- Budget hạn chế
- Muốn triển khai nhanh
Ví dụ use cases:
- 💬 Chatbot customer support
- 📚 Knowledge base search
- 📊 Document Q&A
- 🔍 Internal search engine
- 📰 News/research assistant
Khi nào dùng Fine-tuning?
✅ Fine-tuning phù hợp khi:
- Cần "dạy" mô hình một hành vi cố định
- Thay đổi phong cách viết/nói
- Tùy chỉnh format output
- Dữ liệu ít thay đổi
- Cần performance cao nhất
Ví dụ use cases:
- ✍️ Content generation với style cụ thể
- 🎨 Creative writing
- 💻 Code generation cho framework cụ thể
- 🌐 Translation với terminology riêng
Có thể kết hợp RAG + Fine-tuning?
Có! Đây là approach tốt nhất:
1. Fine-tune mô hình cho:
- Domain-specific language
- Company tone/style
- Output format
2. Sử dụng RAG cho:
- Updated knowledge
- Factual information
- Source citation
Kết quả:
- ✅ Best of both worlds
- ✅ Style phù hợp + Knowledge cập nhật
- ✅ Performance cao + Flexibility
Ưu điểm và hạn chế của RAG
Ưu điểm
1. Giảm hallucination, tăng độ tin cậy
Hallucination rate:
LLM thuần: 20-30%
RAG: 3-8%
→ Giảm 70-85%
2. Dễ cập nhật dữ liệu
Update time:
Fine-tuning: 1-2 tuần
RAG: Vài phút
→ Nhanh hơn 1000x
3. Tiết kiệm chi phí triển khai
Total cost (1 năm):
Fine-tuning: $50,000-200,000
RAG: $5,000-20,000
→ Rẻ hơn 10x
4. Phù hợp với hệ thống chatbot và AI doanh nghiệp
- ✅ Dễ integrate với existing systems
- ✅ Scalable
- ✅ Maintainable
- ✅ Transparent
Hạn chế
1. Phụ thuộc vào chất lượng dữ liệu truy xuất
Vấn đề:
- ❌ Dữ liệu sai → Câu trả lời sai
- ❌ Dữ liệu thiếu → Không trả lời được
- ❌ Dữ liệu lỗi thời → Thông tin cũ
Giải pháp:
- ✅ Data quality control
- ✅ Regular updates
- ✅ Version control
- ✅ Metadata management
2. Triển khai phức tạp hơn LLM thuần
Components cần có:
1. LLM (GPT, Claude, etc.)
2. Embedding model
3. Vector database
4. Search infrastructure
5. Document processing pipeline
6. API integration
Yêu cầu kỹ thuật:
- Backend development
- Database management
- DevOps
- Monitoring & logging
3. Yêu cầu hạ tầng lưu trữ và tìm kiếm
Infrastructure needed:
- 💾 Storage: 100GB - 10TB+
- 🔍 Vector DB: Pinecone, Weaviate
- ⚡ Fast retrieval: < 100ms
- 🔄 Sync pipeline
Chi phí ước tính:
Storage: $50-500/tháng
Vector DB: $100-1,000/tháng
Compute: $200-2,000/tháng
Total: $350-3,500/tháng
4. Thách thức về bảo mật và quyền riêng tư dữ liệu

Rủi ro:
- 🔓 Data leakage
- 🔓 Unauthorized access
- 🔓 Privacy violation
- 🔓 Compliance issues
Giải pháp:
- ✅ Access control
- ✅ Data encryption
- ✅ Audit logging
- ✅ GDPR/HIPAA compliance
- ✅ Data anonymization
Ứng dụng thực tế của Retrieval-Augmented Generation
RAG đang được ứng dụng rộng rãi trong nhiều lĩnh vực:
1. Chatbot & hệ thống hỏi đáp thông minh
Use case: Customer support chatbot
Trước RAG:
User: "Làm sao để reset password?"
Bot: "Bạn có thể reset password bằng cách..."
(Thông tin chung chung, có thể sai)
Với RAG:
User: "Làm sao để reset password?"
Bot: "Để reset password, bạn làm theo các bước sau:
1. Vào trang login
2. Click 'Forgot password'
3. Nhập email đã đăng ký
4. Check email và click link reset
Nguồn: User Guide v2.3, trang 12"
Lợi ích:
- ✅ Trả lời chính xác 24/7
- ✅ Giảm tải cho support team
- ✅ Consistent answers
- ✅ Multilingual support
2. Công cụ tìm kiếm thế hệ mới
Ví dụ: Perplexity.ai, Bing Chat
Khác biệt với Google search:
| | Google Search | RAG Search | | ------------- | ---------------- | ------------------- | | Output | List of links | Direct answer | | Source | Must click links | Cited in answer | | Context | None | Understands context | | Follow-up | New search | Conversational |
Use case:
Query: "So sánh iPhone 15 Pro và Samsung S24 Ultra
về camera và battery life"
RAG Output:
"Dựa trên các review từ TechRadar và GSMArena:
Camera:
- iPhone 15 Pro: 48MP main, 12MP ultrawide...
- Samsung S24 Ultra: 200MP main, 12MP ultrawide...
Battery:
- iPhone 15 Pro: 3,274 mAh, ~23h video
- Samsung S24 Ultra: 5,000 mAh, ~28h video
Nguồn: [TechRadar], [GSMArena]"
3. Tra cứu dữ liệu nội bộ doanh nghiệp
Use case: Enterprise knowledge management
Vấn đề:
- Nhân viên mới khó tìm thông tin
- Tài liệu rải rác nhiều nơi
- Mất thời gian hỏi đồng nghiệp
Giải pháp RAG:
Employee: "Quy trình onboarding nhân viên mới?"
RAG System:
"Quy trình onboarding gồm 5 bước:
1. Chuẩn bị trước ngày nhận việc (HR)
2. Ngày đầu tiên: Orientation
3. Tuần 1: Training cơ bản
4. Tuần 2-4: On-the-job training
5. Tháng 1-3: Mentorship program
Chi tiết từng bước xem tại:
- HR Handbook 2024, Chapter 3
- Onboarding Checklist.xlsx
- Training Schedule.pdf"
ROI:
- ⏰ Tiết kiệm 5-10 giờ/nhân viên/tháng
- 📈 Tăng productivity 20-30%
- 😊 Tăng employee satisfaction
4. Y tế (tra cứu nghiên cứu, hồ sơ bệnh án)
Use case: Medical research assistant
Scenario:
Doctor: "Các nghiên cứu mới nhất về điều trị
ung thư phổi giai đoạn 3 với immunotherapy?"
RAG System:
"Dựa trên 15 nghiên cứu từ PubMed (2023-2024):
Key findings:
1. Pembrolizumab + chemo: OS 22.1 tháng vs 16.5 tháng
2. Nivolumab: Response rate 45% vs 32%
3. Combination therapy: Tăng survival 30%
Top 3 studies:
- KEYNOTE-189 (NEJM, 2024)
- CheckMate-227 (Lancet, 2023)
- IMpower150 (JCO, 2023)
[Full citations và links]"
Lợi ích:
- ✅ Cập nhật research mới nhất
- ✅ Evidence-based medicine
- ✅ Tiết kiệm thời gian research
- ✅ Better patient outcomes
5. Tài chính (phân tích báo cáo, dữ liệu thị trường)
Use case: Financial analyst assistant
Scenario:
Analyst: "Phân tích performance của VNIndex
trong Q1 2024 và factors ảnh hưởng?"
RAG System:
"Phân tích VNIndex Q1 2024:
Performance:
- Open: 1,129 điểm (02/01/2024)
- Close: 1,258 điểm (29/03/2024)
- Tăng: +11.4%
Key factors:
1. FDI tăng 15% YoY
2. Lãi suất giảm 0.5%
3. Earnings growth: +18% YoY
4. P/E ratio: 15.2 (attractive)
Nguồn:
- VNIndex Report Q1 2024
- SSI Research
- VCBS Market Analysis"
6. Giáo dục & nghiên cứu học thuật
Use case: Academic research assistant
Scenario:
Student: "Tóm tắt các lý thuyết chính về
machine learning trong 5 năm gần đây?"
RAG System:
"5 breakthrough theories (2019-2024):
1. Transformers & Attention (2019)
- Paper: "Attention is All You Need"
- Impact: Foundation cho GPT, BERT
2. Self-supervised Learning (2020)
- Paper: "A Simple Framework for Contrastive Learning"
- Impact: Giảm 90% labeled data needed
3. Few-shot Learning (2021)
- Paper: "Language Models are Few-Shot Learners"
- Impact: GPT-3 capabilities
4. Diffusion Models (2022)
- Paper: "Denoising Diffusion Probabilistic Models"
- Impact: DALL-E, Stable Diffusion
5. Constitutional AI (2023)
- Paper: "Constitutional AI: Harmlessness from AI Feedback"
- Impact: Safer AI systems
[Full papers với citations]"
Kiến trúc kỹ thuật của RAG system
Components chính
┌─────────────────────────────────────────┐
│ User Interface (UI) │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ Query Processing │
│ - Intent detection │
│ - Query expansion │
│ - Embedding generation │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ Retrieval System │
│ - Vector search │
│ - Ranking │
│ - Filtering │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ Context Assembly │
│ - Document selection │
│ - Prompt construction │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ LLM Generation │
│ - GPT-4 / Claude / LLaMA │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ Response Post-processing │
│ - Source citation │
│ - Formatting │
│ - Quality check │
└─────────────────────────────────────────┘
Tech stack phổ biến
Embedding Models:
- OpenAI text-embedding-ada-002
- Sentence-BERT
- Cohere embeddings
Vector Databases:
- Pinecone (managed)
- Weaviate (open-source)
- ChromaDB (lightweight)
- FAISS (Facebook)
LLMs:
- GPT-4, GPT-3.5 (OpenAI)
- Claude 3 (Anthropic)
- LLaMA 2 (Meta)
- Gemini (Google)
Frameworks:
- LangChain
- LlamaIndex
- Haystack
Best Practices khi triển khai RAG
1. Data preparation
Checklist:
- [ ] Clean và structure data
- [ ] Chunk documents appropriately (512-1024 tokens)
- [ ] Add metadata (source, date, author)
- [ ] Remove duplicates
- [ ] Version control
2. Embedding strategy
Tips:
- Use domain-specific embeddings nếu có
- Experiment với chunk size
- Add overlap giữa chunks
- Store metadata cùng embeddings
3. Retrieval optimization
Techniques:
- Hybrid search (vector + keyword)
- Re-ranking retrieved documents
- Query expansion
- Filtering by metadata
4. Prompt engineering
Template tốt:
You are a helpful assistant. Answer based on the context.
Context:
{retrieved_docs}
Question: {question}
Instructions:
- Be accurate and concise
- Cite sources
- If unsure, say "I don't have enough information"
Answer:
5. Monitoring & evaluation
Metrics:
- Retrieval precision & recall
- Answer accuracy
- Response time
- User satisfaction
- Cost per query
Kết luận
Qua bài viết, có thể thấy Retrieval-Augmented Generation (RAG) không chỉ là một kỹ thuật AI mới, mà còn là giải pháp then chốt để xây dựng các hệ thống trí tuệ nhân tạo chính xác, minh bạch và dễ mở rộng.
Tóm tắt 5 điểm chính:
1. RAG là gì?
- Kết hợp retrieval + LLM
- Truy xuất dữ liệu thời gian thực
- Sinh câu trả lời có nguồn gốc
2. Lợi ích chính:
- Giảm hallucination (70-85%)
- Cập nhật dễ dàng (phút vs tuần)
- Tiết kiệm chi phí (10x rẻ hơn)
- Minh bạch, có thể verify
3. So với Fine-tuning:
- RAG: Cập nhật thường xuyên
- Fine-tuning: Behavior cố định
- Có thể kết hợp cả hai
4. Ứng dụng rộng rãi:
- Chatbot & customer support
- Enterprise search
- Medical research
- Financial analysis
- Education
5. Thách thức:
- Phụ thuộc data quality
- Triển khai phức tạp
- Yêu cầu infrastructure
- Bảo mật dữ liệu
Thông điệp cuối cùng:
Trong bối cảnh doanh nghiệp ngày càng yêu cầu AI phải đáng tin cậy và cập nhật liên tục, RAG hứa hẹn sẽ trở thành nền tảng quan trọng, góp phần định hình thế hệ AI thông minh tiếp theo.
Tài nguyên học tập
📚 Papers:
- "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (Lewis et al., 2020)
- "REALM: Retrieval-Augmented Language Model Pre-Training" (Guu et al., 2020)
🛠️ Frameworks:
- LangChain
- LlamaIndex
- Haystack
- Semantic Kernel
💻 Tutorials:
- OpenAI RAG Guide
- Pinecone RAG Tutorial
- LangChain Documentation
🎥 Videos:
- "RAG Explained" by AI Explained
- "Building RAG Systems" by DeepLearning.AI
Bạn muốn triển khai RAG cho doanh nghiệp?
📞 Hotline: 0947577892 (Zalo)
🌐 Website: hotrolaptrinh.com
💼 Email: khoilam.dev@gmail.com
Xây dựng AI đáng tin cậy với RAG! 🚀






