Fine-tuning AI là gì? Cách mô hình được tinh chỉnh cho bài toán thực tế
Fine-tuning giúp tùy chỉnh mô hình AI sẵn có cho bài toán cụ thể, tiết kiệm thời gian và chi phí. Tìm hiểu nguyên lý hoạt động, ứng dụng và thách thức khi triển khai Fine-tuning.
Fine-tuning AI là gì? Cách mô hình được tinh chỉnh cho bài toán thực tế
Trong thời đại mà trí tuệ nhân tạo đang dần trở nên không thể thiếu trong nhiều ngành nghề, nhu cầu tùy biến các mô hình AI sao cho phù hợp với từng lĩnh vực cụ thể ngày càng cấp thiết.
Việc xây dựng một mô hình từ đầu không chỉ tốn kém thời gian và chi phí mà còn đòi hỏi khối lượng dữ liệu lớn. Đây là lúc Fine-tuning, hay còn gọi là tinh chỉnh mô hình, phát huy vai trò của mình.
Vậy Fine-tuning là gì và được ứng dụng ra sao? Hãy cùng tìm hiểu trong bài viết dưới đây.
Fine-tuning là gì?
Fine-tuning, hay tinh chỉnh mô hình, là cách giúp mô hình trí tuệ nhân tạo học nhanh hơn nhờ tận dụng những gì đã được học trước đó.
Thay vì huấn luyện một mô hình mới từ đầu tốn nhiều thời gian và dữ liệu, ta dùng một mô hình đã được huấn luyện sẵn (pre-trained model), sau đó điều chỉnh các thông số bên trong để nó phù hợp với một bài toán mới.
 Mô hình Fine-tuning hỗ trợ các mô hình AI học dữ liệu nhanh hơn
Mô hình Fine-tuning hỗ trợ các mô hình AI học dữ liệu nhanh hơn
Định nghĩa kỹ thuật
Fine-tuning là quá trình:
- Lấy một mô hình đã được huấn luyện trên tập dữ liệu lớn
- Điều chỉnh (fine-tune) các tham số của mô hình
- Sử dụng tập dữ liệu nhỏ hơn, chuyên biệt hơn
- Để mô hình thích nghi với tác vụ cụ thể
So sánh: Training từ đầu vs Fine-tuning
| | Training từ đầu | Fine-tuning | | --------------------- | ------------------ | --------------------------- | | Dữ liệu cần | Hàng triệu samples | Hàng nghìn samples | | Thời gian | Tuần/tháng | Giờ/ngày | | Chi phí | Rất cao | Thấp hơn nhiều | | GPU cần | Nhiều GPU mạnh | 1-2 GPU | | Kiến thức ban đầu | Không có | Có sẵn từ pre-trained model | | Độ chính xác | Cao (nếu đủ data) | Cao với ít data |
Tại sao Fine-tuning lại quan trọng trong việc phát triển AI?
Trong bối cảnh AI ngày càng được ứng dụng rộng rãi vào các lĩnh vực khác nhau, Fine-tuning trở thành bước quan trọng giúp mô hình thích nghi nhanh chóng, hoạt động hiệu quả.
1. Hiệu quả về tài nguyên
Fine-tuning giúp tiết kiệm đáng kể thời gian và chi phí.
So sánh chi phí:
Training từ đầu:
- Dữ liệu: 10M+ samples
- GPU: 8x A100 (80GB)
- Thời gian: 2-4 tuần
- Chi phí: $50,000 - $200,000
Fine-tuning:
- Dữ liệu: 1K-10K samples
- GPU: 1-2x A100
- Thời gian: 2-8 giờ
- Chi phí: $100 - $1,000
Lợi ích:
- ✅ Không cần xây dựng mô hình từ đầu
- ✅ Không cần hàng triệu dữ liệu
- ✅ Không cần hạ tầng GPU khủng
- ✅ Triển khai nhanh hơn trong thực tế
2. Cải thiện hiệu suất
Mô hình Fine-tuning sẽ hoạt động tốt hơn trong những tình huống cụ thể.
Ví dụ:
Mô hình gốc (GPT-3):
- Hiểu ngôn ngữ tổng quát
- Accuracy: 70% trên domain cụ thể
Sau Fine-tuning:
- Hiểu ngữ cảnh chuyên ngành
- Accuracy: 90-95% trên domain đó
Tại sao hiệu quả hơn?
- Bắt đầu từ nền tảng đã hiểu cấu trúc dữ liệu chung
- Được tinh chỉnh cho bài toán chuyên biệt
- Kết quả chính xác và hiệu quả hơn
3. Tiết kiệm dữ liệu
Một trong những lợi thế lớn của Fine-tuning là khả năng hoạt động tốt ngay cả khi chỉ có một lượng nhỏ dữ liệu.
Ví dụ thực tế:
| Task | Training từ đầu | Fine-tuning | | ------------------------ | ------------------ | -------------------- | | Phân loại văn bản | 100K+ samples | 1K-5K samples | | Nhận diện hình ảnh | 1M+ images | 500-2K images | | Chatbot chuyên ngành | 10M+ conversations | 1K-10K conversations | | Code generation | Toàn bộ GitHub | 500-5K code snippets |
Nhờ kế thừa kiến thức từ mô hình gốc:
- ✅ Không cần hàng triệu mẫu để học
- ✅ Vẫn hiểu và phản hồi tốt trong ngữ cảnh mới
- ✅ Tiết kiệm dữ liệu đáng kể
Nguyên lý hoạt động của Fine-tuning
Mô hình Fine-tuning hoạt động dựa trên quy trình gồm các bước sau:
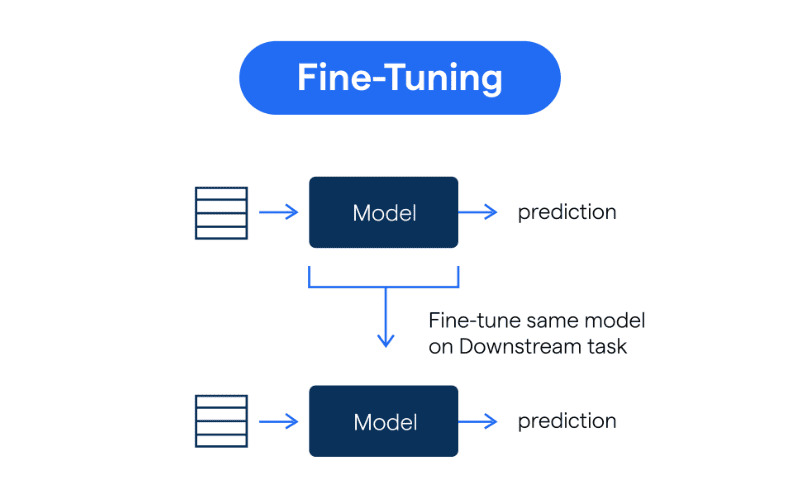 Fine-tuning hoạt động dựa trên quy trình gồm các bước phối hợp chặt chẽ
Fine-tuning hoạt động dựa trên quy trình gồm các bước phối hợp chặt chẽ
Bước 1: Chọn một mô hình đã huấn luyện sẵn
Trước tiên, ta lựa chọn một mô hình đã được huấn luyện trên tập dữ liệu lớn và đa dạng.
Ví dụ các pre-trained models phổ biến:
Cho Computer Vision:
- ResNet, VGG, EfficientNet
- Đã học trên ImageNet (14M images)
Cho NLP:
- BERT, GPT, LLaMA
- Đã học trên hàng tỷ từ
Cho Code:
- CodeLLaMA, StarCoder
- Đã học trên GitHub
Mô hình này đã học được:
- Những đặc trưng tổng quát
- Có thể áp dụng trong nhiều bài toán khác nhau
Bước 2: Giữ nguyên các phần đặc trưng được huấn luyện từ trước
Các tầng đầu của mô hình thường học được những đặc trưng cơ bản và phổ quát từ tập dữ liệu lớn ban đầu.
Ví dụ trong Computer Vision:
Layer 1-2: Phát hiện edges, corners
Layer 3-4: Phát hiện textures, patterns
Layer 5-6: Phát hiện parts (mắt, mũi, bánh xe)
Layer 7+: Phát hiện objects (mặt người, xe hơi)
Trong quá trình Fine-tuning:
- ✅ Các tầng này thường được giữ nguyên (frozen)
- ✅ Hoặc ít khi được cập nhật
- ✅ Giúp tiết kiệm tài nguyên khi huấn luyện
- ✅ Giữ lại những kiến thức cốt lõi
Bước 3: Điều chỉnh các lớp dữ liệu sau
Các tầng phía sau của mô hình thường đảm nhận việc trích xuất những đặc trưng chuyên biệt hơn.
Trong quá trình Fine-tuning:
- Các tầng này sẽ được huấn luyện lại
- Điều chỉnh trọng số sao cho phù hợp với mục tiêu mới
- Thường thêm các tầng mới cho task cụ thể
Ví dụ:
# Freeze early layers
for param in model.base_layers.parameters():
param.requires_grad = False
# Unfreeze later layers
for param in model.top_layers.parameters():
param.requires_grad = True
# Add new classification head
model.classifier = nn.Linear(512, num_classes)
Bước 4: Áp dụng tốc độ học thấp hơn
Trong quá trình Fine-tuning, việc áp dụng tốc độ học thấp hơn so với khi huấn luyện từ đầu là rất quan trọng.
Tại sao?
- Giúp mô hình chỉ điều chỉnh nhẹ nhàng các trọng số
- Tránh làm mất đi các kiến thức nền tảng
- Đảm bảo mô hình thích nghi hiệu quả với bài toán mới
Ví dụ learning rates:
Training từ đầu: lr = 1e-3 (0.001)
Fine-tuning: lr = 1e-5 (0.00001)
→ Thấp hơn 100 lần
Kỹ thuật nâng cao:
- Differential learning rates: Các layer khác nhau có lr khác nhau
- Gradual unfreezing: Từ từ unfreeze các layers
- Learning rate scheduling: Giảm dần lr theo thời gian
Bước 5: Đánh giá và điều chỉnh
Sau khi hoàn tất quá trình Fine-tuning, việc đánh giá hiệu quả hoạt động của mô hình trên từng tình huống cụ thể rất quan trọng.
Metrics cần theo dõi:
- Accuracy, Precision, Recall, F1-score
- Loss (training & validation)
- Inference time
- Model size
Dựa trên kết quả đánh giá:
- ✅ Điều chỉnh các tham số như tốc độ học
- ✅ Mở rộng thêm các lớp khác
- ✅ Cải tiến nhằm tối ưu hóa hiệu suất
Khi nào cần sử dụng Fine-tuning?
Fine-tuning trở thành giải pháp hiệu quả trong nhiều trường hợp nhờ khả năng tùy chỉnh mô hình sẵn có để đáp ứng các yêu cầu cụ thể như:
1. Điều chỉnh theo các tình huống cụ thể
Khi có một mô hình ngôn ngữ đã được huấn luyện trước, việc Fine-tuning cho phép mô hình thích nghi hiệu quả với các nhiệm vụ cụ thể.
Ví dụ:
Mô hình gốc: GPT-3 (general purpose)
Fine-tune cho:
- Phân tích cảm xúc khách hàng
- Tạo nội dung marketing
- Tóm tắt văn bản pháp lý
- Chatbot chăm sóc khách hàng
- Code review và suggestion
Lợi ích:
- Không cần đào tạo lại từ đầu
- Hiệu quả cao với domain cụ thể
- Nhanh chóng triển khai
2. Bảo mật dữ liệu
Trong trường hợp xử lý dữ liệu nhạy cảm, quá trình Fine-tuning có thể được thực hiện trực tiếp trên hệ thống nội bộ.
Use cases:
- 🏥 Y tế: Dữ liệu bệnh nhân
- 🏦 Tài chính: Giao dịch, thông tin khách hàng
- 🏛️ Chính phủ: Dữ liệu nhạy cảm quốc gia
- 🏢 Doanh nghiệp: Trade secrets, IP
Lợi ích:
- ✅ Dữ liệu không rời khỏi môi trường kiểm soát
- ✅ Đáp ứng các yêu cầu về bảo mật
- ✅ Tuân thủ quy định (GDPR, HIPAA)
3. Hạn chế về dữ liệu
Khi tập dữ liệu có hạn, Fine-tuning cho phép tận dụng kiến thức từ mô hình đã được đào tạo trước.
Scenarios:
Startup mới:
- Chưa có nhiều dữ liệu khách hàng
- Budget hạn chế
→ Fine-tune mô hình sẵn có
Ngành niche:
- Ít dữ liệu công khai
- Domain-specific knowledge
→ Fine-tune với data có sẵn
Kết quả:
- Đạt hiệu quả cao mà không đòi hỏi một lượng lớn dữ liệu mới
- Nhanh chóng có được mô hình hoạt động tốt
4. Quá trình học liên tục
Fine-tuning hỗ trợ cập nhật và điều chỉnh mô hình định kỳ nhằm thích ứng với sự thay đổi của dữ liệu và yêu cầu theo thời gian.
Ví dụ:
Chatbot customer service:
- Tháng 1: Fine-tune với Q&A hiện tại
- Tháng 3: Re-fine-tune với câu hỏi mới
- Tháng 6: Update với sản phẩm mới
→ Continuous improvement
Lợi ích:
- Không cần bắt đầu huấn luyện lại từ đầu
- Mô hình luôn cập nhật
- Adapt với thay đổi của thị trường
Ứng dụng của Fine-tuning
Fine-tuning được ứng dụng rộng rãi trong nhiều lĩnh vực để nâng cao hiệu suất mô hình trên các tác vụ cụ thể, bao gồm:
1. Trong y tế và chăm sóc sức khỏe
Use case: Chẩn đoán bệnh từ hình ảnh y khoa
Các nhà khoa học có thể sử dụng Fine-tuning để điều chỉnh một mô hình xử lý hình ảnh đã được huấn luyện sẵn, dựa trên một tập ảnh CT nhỏ đặc trưng cho bệnh đó.
Quy trình:
1. Mô hình gốc: ResNet pre-trained trên ImageNet
2. Fine-tune: Với 1,000-5,000 ảnh CT của bệnh cụ thể
3. Kết quả: Nhận diện chính xác 90-95% dấu hiệu bệnh
Ứng dụng cụ thể:
- 🔬 Phát hiện ung thư từ X-ray
- 🧠 Chẩn đoán bệnh não từ MRI
- 👁️ Nhận diện bệnh võng mạc
- 🫁 Phát hiện COVID-19 từ CT scan
Lợi ích:
- Hỗ trợ hiệu quả cho việc chẩn đoán
- Giảm thời gian chẩn đoán
- Tăng độ chính xác
- Hỗ trợ bác sĩ ra quyết định
2. Trong bán lẻ và thương mại điện tử
 Fine-tuning giúp doanh nghiệp khai thác thông tin từ khách hàng như lịch sử mua hàng hay đánh giá sản phẩm
Fine-tuning giúp doanh nghiệp khai thác thông tin từ khách hàng như lịch sử mua hàng hay đánh giá sản phẩm
Use case: Hệ thống gợi ý sản phẩm cá nhân hóa
Mô hình Fine-tuning có thể điều chỉnh mô hình đã được huấn luyện trước dựa trên dữ liệu tương tác của người dùng.
Dữ liệu sử dụng:
- 📊 Lịch sử mua hàng
- ⭐ Đánh giá sản phẩm
- 👁️ Lịch sử xem sản phẩm
- 🛒 Sản phẩm trong giỏ hàng
- 🔍 Lịch sử tìm kiếm
Kết quả:
Trước Fine-tuning:
- Click-through rate: 2%
- Conversion rate: 0.5%
Sau Fine-tuning:
- Click-through rate: 5-7%
- Conversion rate: 1.5-2%
→ Tăng 3-4 lần hiệu quả
Ứng dụng khác:
- 💬 Chatbot tư vấn sản phẩm
- 🏷️ Tự động phân loại sản phẩm
- 📝 Tạo mô tả sản phẩm
- 🎯 Personalized marketing
3. Hỗ trợ chăm sóc khách hàng
Use case: Chatbot chăm sóc khách hàng thông minh
Fine-tuning được dùng để điều chỉnh mô hình ngôn ngữ lớn (LLM) dựa trên dữ liệu các cuộc trò chuyện hỗ trợ khách hàng trước đây.
Quy trình:
1. Mô hình gốc: GPT-3.5 hoặc LLaMA
2. Fine-tune với:
- 5,000-10,000 cuộc hội thoại thực tế
- FAQ của công ty
- Thông tin sản phẩm/dịch vụ
3. Deploy: Chatbot hiểu context công ty
Cải thiện:
| Metric | Before | After Fine-tuning | | ------------------------- | -------- | ----------------- | | Accuracy | 60% | 85-90% | | Response time | 2-3 mins | < 10 seconds | | Customer satisfaction | 3.2/5 | 4.5/5 | | Resolution rate | 40% | 70-80% |
Lợi ích:
- ✅ Trả lời chính xác hơn
- ✅ Phù hợp với sản phẩm/dịch vụ công ty
- ✅ Giảm tải cho nhân viên support
- ✅ Hoạt động 24/7
4. Các ứng dụng khác
Trong giáo dục:
- 📚 Chatbot gia sư cá nhân hóa
- ✍️ Chấm bài tự động
- 📊 Phân tích tiến độ học tập
Trong tài chính:
- 💰 Phát hiện gian lận
- 📈 Dự đoán thị trường
- 🤖 Robo-advisor
Trong sản xuất:
- 🔧 Phát hiện lỗi sản phẩm
- 🏭 Tối ưu quy trình sản xuất
- 📦 Quản lý chất lượng
Thách thức và rủi ro khi triển khai Fine-tuning
Mặc dù Fine-tuning mang lại nhiều lợi ích trong việc tùy chỉnh mô hình AI nhưng quá trình này cũng đối mặt với một số thách thức và rủi ro cần được lưu ý:
1. Yêu cầu về dữ liệu chất lượng cao
Fine-tuning đòi hỏi dữ liệu chuyên biệt, chính xác và có độ tin cậy cao.
Vấn đề:
- ❌ Dữ liệu có lỗi → Mô hình học sai
- ❌ Dữ liệu thiên lệch → Mô hình thiên lệch
- ❌ Dữ liệu không đại diện → Kém hiệu quả
Yêu cầu dữ liệu:
Chất lượng:
- Accurate: Chính xác 95%+
- Clean: Không có noise, duplicates
- Labeled: Có nhãn đúng
- Representative: Đại diện cho use case
Số lượng:
- Minimum: 500-1,000 samples
- Good: 5,000-10,000 samples
- Excellent: 50,000+ samples
Giải pháp:
- ✅ Data cleaning và validation
- ✅ Human review cho critical data
- ✅ Data augmentation nếu cần
- ✅ Active learning để thu thập data tốt hơn
2. Rủi ro về bảo mật và riêng tư
Việc sử dụng dữ liệu nhạy cảm trong Fine-tuning nếu không được quản lý chặt chẽ có thể dẫn đến rò rỉ thông tin.
Rủi ro:
- 🔓 Model memorization: Mô hình nhớ dữ liệu training
- 🔓 Data leakage: Thông tin nhạy cảm bị lộ
- 🔓 Model inversion: Có thể reconstruct training data
- 🔓 Privacy violation: Vi phạm quyền riêng tư
Ví dụ:
Fine-tune chatbot với email khách hàng
→ Mô hình có thể leak thông tin cá nhân
→ Vi phạm GDPR
Giải pháp:
- ✅ Data anonymization
- ✅ Differential privacy
- ✅ Secure enclaves
- ✅ Regular security audits
- ✅ Compliance với GDPR, HIPAA
3. Tốn kém chi phí và thời gian
Quá trình Fine-tuning vẫn cần tài nguyên tính toán đáng kể.
Chi phí ước tính:
| Model Size | GPU Needed | Time | Cost | | ------------------------ | ---------- | ---------- | ------------ | | Small (< 1B params) | 1x A100 | 2-4 hours | $50-100 | | Medium (1-7B params) | 2-4x A100 | 8-24 hours | $200-500 | | Large (7-70B params) | 8-16x A100 | 1-3 days | $1,000-5,000 |
Thách thức:
- ⚠️ Cần GPU mạnh
- ⚠️ Tốn thời gian với mô hình lớn
- ⚠️ Chi phí cloud computing
- ⚠️ Cần expertise để optimize
Giải pháp:
- ✅ Sử dụng kỹ thuật LoRA, QLoRA (giảm 90% memory)
- ✅ Gradient checkpointing
- ✅ Mixed precision training
- ✅ Cloud services với spot instances
4. Quá khớp dữ liệu (Overfitting)
Nếu tập dữ liệu Fine-tuning quá ít hoặc quá giống nhau, mô hình có xu hướng học thuộc lòng từng mẫu dữ liệu thay vì hiểu ra các quy luật chung.
Dấu hiệu overfitting:
Training accuracy: 98%
Validation accuracy: 65%
→ Gap lớn = Overfitting
Hậu quả:
- ❌ Hoạt động tốt trên training data
- ❌ Hoạt động kém trên data mới
- ❌ Không generalize được
Giải pháp:
- ✅ Data augmentation: Tăng đa dạng dữ liệu
- ✅ Regularization: L1, L2, dropout
- ✅ Early stopping: Dừng khi validation loss tăng
- ✅ Cross-validation: Đánh giá đúng performance
- ✅ More data: Thu thập thêm dữ liệu
5. Catastrophic Forgetting
Mô hình có thể quên kiến thức ban đầu khi Fine-tune quá mạnh.
Ví dụ:
Mô hình gốc: Hiểu 100 ngôn ngữ
Fine-tune: Chỉ với tiếng Việt
Kết quả: Quên các ngôn ngữ khác
Giải pháp:
- ✅ Sử dụng learning rate thấp
- ✅ Freeze một số layers
- ✅ Continual learning techniques
- ✅ Mix original data vào training
Best Practices khi Fine-tuning
1. Chuẩn bị dữ liệu
Checklist:
- [ ] Clean data (remove noise, duplicates)
- [ ] Balance classes (nếu classification)
- [ ] Split data: 80% train, 10% validation, 10% test
- [ ] Data augmentation nếu cần
- [ ] Verify data quality
2. Chọn mô hình phù hợp
Tiêu chí:
- ✅ Task tương tự với pre-training
- ✅ Model size phù hợp với resources
- ✅ License cho phép commercial use
- ✅ Community support tốt
3. Hyperparameter tuning
Quan trọng nhất:
learning_rate = 1e-5 # Thấp hơn training từ đầu
batch_size = 16-32 # Tùy GPU memory
epochs = 3-5 # Ít epochs hơn
warmup_steps = 100 # Warm up learning rate
4. Monitoring và evaluation
Metrics cần track:
- Training loss
- Validation loss
- Accuracy/F1-score
- Inference time
- Memory usage
5. Testing và deployment
Checklist:
- [ ] Test trên diverse test set
- [ ] A/B testing với mô hình cũ
- [ ] Monitor performance in production
- [ ] Set up alerts cho anomalies
- [ ] Plan cho continuous improvement
Tools và Frameworks phổ biến
Hugging Face Transformers
from transformers import AutoModelForSequenceClassification, Trainer
# Load pre-trained model
model = AutoModelForSequenceClassification.from_pretrained(
"bert-base-uncased",
num_labels=2
)
# Fine-tune
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
trainer.train()
PyTorch Lightning
import pytorch_lightning as pl
class FineTuneModel(pl.LightningModule):
def __init__(self, pretrained_model):
super().__init__()
self.model = pretrained_model
def training_step(self, batch, batch_idx):
# Training logic
pass
TensorFlow/Keras
from tensorflow.keras.applications import ResNet50
# Load pre-trained model
base_model = ResNet50(weights='imagenet', include_top=False)
# Freeze base layers
base_model.trainable = False
# Add custom layers
model = Sequential([
base_model,
GlobalAveragePooling2D(),
Dense(num_classes, activation='softmax')
])
Tạm kết
Hy vọng bài viết trên cung cấp thêm thông tin về Fine-tuning là gì.
Tóm tắt 5 điểm chính:
1. Fine-tuning là gì?
- Tinh chỉnh mô hình AI sẵn có cho bài toán cụ thể
- Tận dụng kiến thức đã học trước
- Tiết kiệm thời gian, chi phí và dữ liệu
2. Tại sao quan trọng?
- Hiệu quả về tài nguyên (100x rẻ hơn)
- Cải thiện hiệu suất (20-30% accuracy)
- Tiết kiệm dữ liệu (chỉ cần 1K samples)
3. Khi nào sử dụng?
- Bài toán chuyên biệt
- Hạn chế về dữ liệu
- Yêu cầu bảo mật cao
- Continuous learning
4. Ứng dụng thực tế:
- Y tế: Chẩn đoán bệnh
- Bán lẻ: Gợi ý sản phẩm
- Customer service: Chatbot
- Nhiều lĩnh vực khác
5. Thách thức:
- Cần dữ liệu chất lượng cao
- Rủi ro bảo mật
- Chi phí và thời gian
- Overfitting
Kết luận cuối cùng:
Fine-tuning là một kỹ thuật quan trọng trong lĩnh vực trí tuệ nhân tạo, giúp tùy chỉnh các mô hình đã được huấn luyện sẵn. Từ đó đáp ứng chính xác hơn các yêu cầu chuyên biệt trong nhiều ngành nghề khác nhau.
Bên cạnh những lợi ích nổi bật, quá trình này cũng đặt ra những thách thức và rủi ro. Vì vậy, việc triển khai Fine-tuning cần được thực hiện cẩn trọng, kết hợp với các biện pháp kiểm soát phù hợp để tối ưu hiệu quả và đảm bảo an toàn trong ứng dụng thực tế.
Tài nguyên học tập
📚 Courses:
- Fast.ai - Practical Deep Learning
- Hugging Face Course
- DeepLearning.AI - Transfer Learning
🛠️ Tools:
- Hugging Face Transformers
- PyTorch Lightning
- TensorFlow Hub
- Weights & Biases
📖 Papers:
- "Universal Language Model Fine-tuning" (ULMFiT)
- "BERT: Pre-training of Deep Bidirectional Transformers"
- "LoRA: Low-Rank Adaptation of Large Language Models"
💻 Platforms:
- Google Colab (Free GPU)
- Kaggle Notebooks
- AWS SageMaker
- Azure ML
Bạn cần tư vấn về Fine-tuning AI cho doanh nghiệp?
📞 Hotline: 0947577892 (Zalo)
🌐 Website: hotrolaptrinh.com
💼 Email: khoilam.dev@gmail.com
Tận dụng sức mạnh AI với Fine-tuning! 🚀