Công nghệ tổng hợp giọng nói: Khi AI bắt đầu 'nói chuyện' như con người
Speech Synthesis (TTS) chuyển văn bản thành giọng nói tự nhiên. Thị trường TTS đạt 5 tỷ USD năm 2026. Tìm hiểu nguyên lý hoạt động, kỹ thuật và ứng dụng thực tế.
Công nghệ tổng hợp giọng nói: Khi AI bắt đầu "nói chuyện" như con người
Trong bối cảnh trí tuệ nhân tạo (AI) phát triển mạnh mẽ, công nghệ tổng hợp giọng nói (Speech Synthesis) ngày càng đóng vai trò quan trọng trong giao tiếp giữa con người và máy móc.
Một trong những ứng dụng phổ biến nhất của công nghệ này là Text-to-Speech (TTS) – chuyển đổi văn bản thành giọng nói tự nhiên.

Thị trường Speech Synthesis đang bùng nổ
Theo báo cáo của MarketsandMarkets:
Thị trường Text-to-Speech toàn cầu được dự đoán sẽ đạt 5 tỷ USD vào năm 2026, với tốc độ tăng trưởng kép (CAGR) 14,6%/năm.
Con số này cho thấy:
- 📈 Nhu cầu tích hợp giọng nói thông minh đang tăng nhanh
- 🌐 Ứng dụng rộng rãi trong sản phẩm, dịch vụ số
- 🚀 Xu hướng phát triển mạnh mẽ trên toàn cầu
Vậy Speech Synthesis là gì, hoạt động như thế nào và xu hướng phát triển trong tương lai ra sao?
Speech Synthesis là gì?
Speech Synthesis (tổng hợp giọng nói) là công nghệ cho phép máy tính hoặc phần mềm mô phỏng giọng nói của con người dựa trên dữ liệu và mô hình học máy.
Định nghĩa
Về bản chất, đây là quá trình chuyển đổi văn bản đầu vào thành giọng nói nhân tạo – thường được biết đến với tên gọi Text-to-Speech (TTS).
Input: "Xin chào, tôi là trợ lý ảo"
↓
Speech Synthesis
↓
Output: 🔊 Giọng nói tự nhiên
Chất lượng giọng nói phụ thuộc vào
1. Mô hình ngôn ngữ (Language Model)
- Hiểu ngữ cảnh
- Xử lý ngữ pháp
- Phân tích cú pháp
2. Mô hình âm học (Acoustic Model)
- Tạo ra âm thanh
- Điều chỉnh ngữ điệu
- Tạo nhịp điệu tự nhiên
3. Dữ liệu huấn luyện giọng nói
- Chất lượng recording
- Đa dạng ngữ điệu
- Số lượng dữ liệu
Sự khác biệt với con người
Con người:
- ✅ Hiểu ngữ cảnh tự nhiên
- ✅ Cảm xúc thật
- ✅ Linh hoạt tức thì
Speech Synthesis:
- 🤖 Học từ dữ liệu
- 🤖 Tái tạo ngữ điệu
- 🤖 Phân tích pattern
- 🤖 Tạo âm thanh ngày càng tự nhiên
Không giống con người có khả năng "hiểu" ngữ cảnh, hệ thống Speech Synthesis học cách tái tạo ngữ điệu, nhấn âm và biểu cảm thông qua việc phân tích dữ liệu giọng nói ở quy mô lớn, từ đó tạo ra âm thanh ngày càng tự nhiên và giống người thật.
Speech Synthesis khác gì so với Text-to-Speech (TTS)?
Mặc dù thường được dùng thay thế cho nhau, Speech Synthesis và Text-to-Speech vẫn có sự khác biệt nhất định:
Speech Synthesis (Khái niệm rộng)
Là khái niệm bao quát, bao gồm toàn bộ quá trình tạo ra giọng nói nhân tạo.
Công nghệ này:
- ✅ Chuyển văn bản thành lời nói
- ✅ Tái tạo cảm xúc
- ✅ Điều chỉnh ngữ điệu
- ✅ Kiểm soát nhịp điệu
- ✅ Tùy chỉnh âm sắc
Mục tiêu: Giọng nói trở nên tự nhiên hơn, gần giống con người
Text-to-Speech / TTS (Ứng dụng cụ thể)
Là một nhánh cụ thể của Speech Synthesis, chuyên xử lý việc chuyển văn bản thuần túy thành âm thanh giọng nói.
Đặc điểm:
- 📝 Input: Text
- 🔊 Output: Audio
- 🎯 Focus: Accuracy & clarity
- 🚀 Ứng dụng phổ biến nhất
So sánh trực quan
| | Speech Synthesis | Text-to-Speech (TTS) | | ------------ | -------------------------------- | ------------------------- | | Phạm vi | Rộng (toàn bộ quá trình) | Hẹp (chuyển text → audio) | | Focus | Tự nhiên, cảm xúc, ngữ điệu | Chính xác, rõ ràng | | Ứng dụng | Research, advanced systems | Practical applications | | Ví dụ | Voice cloning, emotion synthesis | Screen readers, GPS |
👉 Nói ngắn gọn: TTS là một phần của Speech Synthesis, còn Speech Synthesis là khái niệm rộng hơn.
Nguyên lý hoạt động của Speech Synthesis
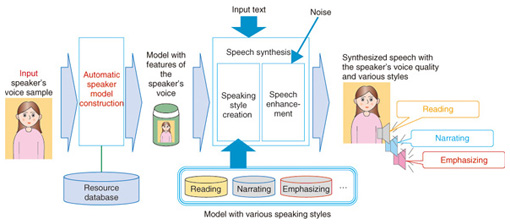
Quy trình tổng hợp giọng nói thường bao gồm ba giai đoạn chính:
1. Chuẩn hóa và phân tích văn bản (Text Normalization)
Hệ thống xử lý văn bản đầu vào bằng cách:
A. Chuẩn hóa số, ngày tháng, ký hiệu
Input: "Giá 1,500,000đ vào 01/01/2024"
Normalized: "Giá một triệu năm trăm nghìn đồng
vào ngày một tháng một năm hai nghìn
không trăm hai mươi bốn"
B. Xử lý từ viết tắt
"TP.HCM" → "Thành phố Hồ Chí Minh"
"Dr." → "Doctor"
"etc." → "et cetera"
C. Xử lý từ đồng âm khác nghĩa
"live" (sống) vs "live" (trực tiếp)
→ Phân biệt dựa trên ngữ cảnh
D. Chuyển văn bản về dạng dễ phát âm
Công nghệ sử dụng:
- Mô hình thống kê
- Mạng nơ-ron (Neural Networks)
- Rule-based systems
- Context analysis
2. Chuyển từ thành âm vị (Grapheme-to-Phoneme)
Văn bản sau khi xử lý sẽ được tách thành âm vị – đơn vị âm thanh nhỏ nhất cấu thành lời nói.
Ví dụ:
Text: "hello"
Phonemes: /h/ /ɛ/ /l/ /oʊ/
Text: "xin chào"
Phonemes: /s/ /i/ /n/ /c/ /a/ /o/
Bước này có thể thông qua:
A. Quy tắc ngôn ngữ (Rule-based)
# Ví dụ rules
"ch" → /tʃ/
"th" → /θ/ hoặc /ð/
"tion" → /ʃən/
B. Mô hình học máy
Input: Graphemes (chữ viết)
Model: G2P (Grapheme-to-Phoneme)
Output: Phonemes (âm vị)
Thách thức:
- Ngôn ngữ không phonetic (như tiếng Anh)
- Từ ngoại lai
- Tên riêng
- Từ đồng âm
3. Tổng hợp âm thanh (Audio Synthesis)
Cuối cùng, hệ thống tạo ra sóng âm thanh từ các âm vị.
Quy trình:
Phonemes → Acoustic Features → Waveform → Audio
Các thông số được điều chỉnh:
- Pitch (cao độ)
- Duration (độ dài)
- Energy (cường độ)
- Prosody (ngữ điệu)
- Intonation (âm điệu)
Các kỹ thuật tổng hợp giọng nói phổ biến
Hiện nay, Speech Synthesis thường dựa trên 4 kỹ thuật chính:
1. Concatenative Synthesis (Tổng hợp nối ghép)
Cách hoạt động:
- Ghép các đoạn ghi âm giọng người có sẵn
- Tạo thành câu nói hoàn chỉnh
Ưu điểm:
- ✅ Giọng tự nhiên (vì dùng giọng người thật)
- ✅ Chất lượng cao
- ✅ Dễ hiểu
Nhược điểm:
- ❌ Kém linh hoạt
- ❌ Cần database lớn
- ❌ Khó tạo giọng mới
- ❌ Không smooth ở chỗ nối
Ví dụ:
Database: ["xin", "chào", "bạn", "tôi", "là"]
Output: "xin" + "chào" + "bạn"
2. Formant Synthesis (Tổng hợp cộng hưởng)
Cách hoạt động:
- Sử dụng mô hình toán học
- Mô phỏng cộng hưởng âm thanh
- Tạo âm thanh từ công thức
Ưu điểm:
- ✅ Nhẹ (không cần database lớn)
- ✅ Ổn định
- ✅ Flexible
- ✅ Real-time
Nhược điểm:
- ❌ Ít tự nhiên
- ❌ Giọng "robot"
- ❌ Khó điều chỉnh
Ứng dụng:
- Embedded systems
- Low-resource devices
- Real-time applications
3. Articulatory Synthesis (Tổng hợp mô phỏng phát âm)
Cách hoạt động:
- Mô phỏng hoạt động của:
- Miệng
- Lưỡi
- Dây thanh quản
- Hệ hô hấp
Ưu điểm:
- ✅ Độ chi tiết cao
- ✅ Realistic
- ✅ Có thể điều chỉnh từng yếu tố
Nhược điểm:
- ❌ Phức tạp
- ❌ Tốn tài nguyên
- ❌ Khó implement
Ứng dụng:
- Research
- Medical training
- Speech therapy
4. Deep Learning-based Synthesis (Tổng hợp dựa trên AI) ⭐
Cách hoạt động:
- Ứng dụng mạng nơ-ron sâu
- Học từ dữ liệu lớn
- End-to-end learning
Kiến trúc phổ biến:
A. WaveNet (Google, 2016)
Input: Text
↓
Mel-spectrogram
↓
WaveNet (CNN)
↓
Raw audio waveform
B. Tacotron 2 (Google, 2017)
Text → Encoder → Attention → Decoder → Mel-spec
Mel-spec → WaveNet → Audio
C. FastSpeech (Microsoft, 2019)
Text → Transformer → Mel-spec → Vocoder → Audio
(Faster, more stable)
Ưu điểm:
- ✅ Giọng nói tự nhiên nhất
- ✅ Giàu cảm xúc
- ✅ Gần giống con người
- ✅ Flexible & scalable
- ✅ Multi-speaker support
Nhược điểm:
- ❌ Cần dữ liệu lớn
- ❌ Tốn GPU
- ❌ Training time dài
👉 Đây là xu hướng chủ đạo hiện nay và được sử dụng bởi Google, Amazon, Microsoft, OpenAI.
Ứng dụng của công nghệ tổng hợp giọng nói

1. Hỗ trợ người khuyết tật
Speech Synthesis giúp người khiếm thị hoặc người gặp khó khăn trong giao tiếp tiếp cận nội dung văn bản thông qua giọng nói.
Ứng dụng cụ thể:
A. Screen Readers
- JAWS (Job Access With Speech)
- NVDA (NonVisual Desktop Access)
- VoiceOver (Apple)
- TalkBack (Android)
B. Communication Aids
- Thiết bị hỗ trợ giao tiếp
- AAC devices (Augmentative and Alternative Communication)
C. Reading Assistance
- Đọc sách điện tử
- Đọc email, tin nhắn
- Đọc tài liệu học tập
Lợi ích:
- ✅ Xóa bỏ rào cản thông tin
- ✅ Nâng cao chất lượng sống
- ✅ Độc lập hơn trong sinh hoạt
- ✅ Tiếp cận giáo dục, công việc
2. Trợ lý ảo và thiết bị thông minh
Các trợ lý ảo sử dụng tổng hợp giọng nói để giao tiếp tự nhiên với người dùng.
Ví dụ phổ biến:
| Trợ lý | Công ty | Thiết bị | | -------------------- | --------- | -------------------------- | | Siri | Apple | iPhone, iPad, Mac, HomePod | | Google Assistant | Google | Android, Google Home | | Alexa | Amazon | Echo, Fire TV | | Cortana | Microsoft | Windows, Xbox | | Bixby | Samsung | Galaxy devices |
Use cases:
User: "Thời tiết hôm nay thế nào?"
Assistant: 🔊 "Hôm nay trời nắng, nhiệt độ 28 độ C"
User: "Đặt hẹn 3 giờ chiều"
Assistant: 🔊 "Đã đặt hẹn lúc 3 giờ chiều"
User: "Mở nhạc"
Assistant: 🔊 "Đang phát playlist yêu thích của bạn"
Lợi ích:
- ✅ Hands-free interaction
- ✅ Natural conversation
- ✅ 24/7 availability
- ✅ Multi-tasking support
3. Giáo dục và đào tạo trực tuyến
Công nghệ này hỗ trợ tạo bài giảng, video học tập, tài liệu đào tạo nhanh chóng.
Ứng dụng:
A. E-learning Platforms
Text content → TTS → Audio lectures
→ Tiết kiệm thời gian & chi phí thu âm
B. Language Learning
- Pronunciation practice
- Listening exercises
- Interactive dialogues
C. Audiobooks
- Chuyển sách thành audio
- Multiple languages
- Adjustable speed
D. Training Materials
- Corporate training
- Safety instructions
- Product tutorials
ROI:
Traditional recording:
- Cost: $100-500/hour
- Time: 1-2 weeks
- Updates: Expensive
TTS:
- Cost: $10-50/hour
- Time: Minutes
- Updates: Easy & cheap
4. Sáng tạo nội dung và marketing
Speech Synthesis giúp doanh nghiệp:
A. Sản xuất video, podcast, bản tin tự động
Workflow:
1. Write script
2. Generate voice with TTS
3. Add to video/podcast
4. Publish
Time saved: 80-90%
Cost saved: 70-85%
B. Cá nhân hóa giọng nói theo thương hiệu
- Brand voice identity
- Consistent tone
- Recognizable sound
C. Mở rộng nội dung đa ngôn ngữ ở quy mô lớn
1 script → 50 languages
Traditional: 6 months, $50K
TTS: 1 week, $5K
Đặc biệt:
AI Voice Cloning cho phép:
- ✅ Tạo giọng nói mang dấu ấn riêng
- ✅ Tăng khả năng nhận diện thương hiệu
- ✅ Kết nối cảm xúc với người dùng
- ✅ Consistency across channels
Use cases:
- 📺 Video marketing
- 📻 Podcast production
- 📱 Social media content
- 🎬 Advertising
- 📧 Email campaigns with audio
5. Các ứng dụng khác
A. Navigation & GPS
- Google Maps
- Waze
- Apple Maps
B. Customer Service
- IVR systems
- Chatbots with voice
- Automated support
C. Gaming
- NPC dialogues
- Dynamic storytelling
- Localization
D. Healthcare
- Medication reminders
- Patient instructions
- Telemedicine
E. Automotive
- In-car assistants
- Navigation
- Notifications
Xu hướng phát triển của Speech Synthesis trong tương lai
Trong thời gian tới, công nghệ tổng hợp giọng nói sẽ tiếp tục phát triển theo hướng:
1. Giọng nói tự nhiên hơn, giàu cảm xúc hơn
Hiện tại:
"Xin chào" (neutral tone)
Tương lai:
"Xin chào!" (excited)
"Xin chào..." (sad)
"Xin chào?" (confused)
"Xin chào~" (friendly)
Công nghệ:
- Emotion synthesis
- Prosody control
- Context-aware generation
- Real-time emotion adaptation
Ví dụ:
Context: User just won a prize
TTS: "Chúc mừng bạn!" (excited, happy tone)
Context: User reported an issue
TTS: "Tôi rất tiếc về điều đó" (empathetic, concerned)
2. Kết hợp với video AI, avatar ảo và nội dung đa phương tiện
Multimodal AI:
Text → Speech + Lip Sync + Facial Expression + Gesture
Ứng dụng:
- 🎭 Virtual influencers
- 👨🏫 AI teachers
- 🎬 Synthetic actors
- 🎮 Game characters
- 📺 News anchors
Công nghệ liên quan:
- Speech-driven facial animation
- Lip sync generation
- Gesture synthesis
- Real-time rendering
3. Cá nhân hóa trải nghiệm người dùng theo thời gian thực
Adaptive TTS:
User preferences:
- Voice: Female, young, friendly
- Speed: 1.2x
- Accent: Southern
- Emotion: Warm
→ TTS adapts automatically
Personalization factors:
- User demographics
- Time of day
- Context
- Mood
- History
Ví dụ:
Morning: Energetic, upbeat voice
Evening: Calm, soothing voice
Urgent notification: Alert, clear voice
Casual chat: Relaxed, friendly voice
4. Zero-shot & Few-shot Voice Cloning
Hiện tại:
- Cần 10-30 phút audio để clone voice
- Training time: Hours
Tương lai:
- Chỉ cần 3-5 giây audio
- Instant cloning
- Real-time adaptation
Ứng dụng:
- Instant voice customization
- Deceased loved ones' voices
- Historical figures
- Multilingual same voice
5. Real-time Speech-to-Speech Translation
Vision:
Speak Vietnamese → Real-time translation →
Output in English with YOUR voice
Technology:
- Speech recognition
- Translation
- Voice cloning
- Real-time synthesis
Impact:
- Breaking language barriers
- Global communication
- Preserve voice identity
6. Ethical AI & Deepfake Detection
Challenges:
- Voice deepfakes
- Misinformation
- Identity theft
Solutions:
- Watermarking
- Authentication
- Detection systems
- Regulations
Thách thức và hạn chế
1. Chất lượng dữ liệu
Vấn đề:
- Cần dữ liệu sạch, chất lượng cao
- Đa dạng về ngữ điệu, cảm xúc
- Expensive to collect
Giải pháp:
- Data augmentation
- Synthetic data generation
- Transfer learning
2. Ngôn ngữ ít tài nguyên
Thách thức:
- Tiếng Việt, Thai, etc.
- Ít dữ liệu training
- Ít research
Giải pháp:
- Multilingual models
- Cross-lingual transfer
- Community contributions
3. Computational cost
Vấn đề:
- Deep learning models tốn GPU
- Real-time synthesis khó
- Expensive to scale
Giải pháp:
- Model compression
- Quantization
- Edge computing
- Cloud services
4. Ethical concerns
Rủi ro:
- Voice deepfakes
- Impersonation
- Misinformation
- Privacy violation
Giải pháp:
- Regulations
- Detection systems
- User consent
- Watermarking
Công cụ và dịch vụ TTS phổ biến
Cloud Services
1. Google Cloud Text-to-Speech
- 220+ voices
- 40+ languages
- WaveNet & Neural2
2. Amazon Polly
- 60+ voices
- 30+ languages
- Neural TTS
3. Microsoft Azure Speech
- 270+ voices
- 110+ languages
- Custom Neural Voice
4. OpenAI TTS
- Natural voices
- Multiple styles
- API access
Open Source
1. Mozilla TTS
- Free & open source
- Multiple architectures
- Community support
2. Coqui TTS
- 1100+ models
- 16 languages
- Easy to use
3. ESPnet
- Research-oriented
- State-of-the-art models
- Flexible
Commercial Tools
1. ElevenLabs
- Voice cloning
- Emotion control
- High quality
2. Murf.ai
- Studio-quality voices
- Easy editing
- Multiple use cases
3. Descript Overdub
- Voice cloning
- Text editing
- Video integration
Kết luận
Có thể thấy, Speech Synthesis đang từng bước thu hẹp khoảng cách giữa con người và công nghệ, mang đến trải nghiệm giao tiếp tự nhiên, trực quan và giàu cảm xúc hơn.
Tóm tắt 5 điểm chính:
1. Speech Synthesis là gì?
- Công nghệ tạo giọng nói nhân tạo
- TTS là ứng dụng phổ biến nhất
- Thị trường đạt 5 tỷ USD năm 2026
2. Nguyên lý hoạt động:
- Text normalization
- Grapheme-to-Phoneme
- Audio synthesis
3. Kỹ thuật chính:
- Concatenative (ghép nối)
- Formant (toán học)
- Articulatory (mô phỏng)
- Deep Learning (AI) ⭐
4. Ứng dụng rộng rãi:
- Accessibility
- Virtual assistants
- Education
- Content creation
- Marketing
5. Xu hướng tương lai:
- Tự nhiên hơn, giàu cảm xúc
- Multimodal AI
- Personalization
- Voice cloning
- Real-time translation
Thông điệp cuối cùng:
Với sự hỗ trợ của trí tuệ nhân tạo hiện đại, công nghệ tổng hợp giọng nói hứa hẹn sẽ tiếp tục bùng nổ và trở thành nền tảng quan trọng trong các sản phẩm số của tương lai.
Speech Synthesis không chỉ dừng lại ở việc "đọc" văn bản, mà còn trở thành cầu nối giao tiếp tự nhiên giữa con người và AI trong giáo dục, y tế, chăm sóc khách hàng, marketing và giải trí.
Tài nguyên học tập
📚 Papers:
- "WaveNet: A Generative Model for Raw Audio" (DeepMind, 2016)
- "Tacotron 2: Natural TTS Synthesis" (Google, 2017)
- "FastSpeech: Fast, Robust and Controllable TTS" (Microsoft, 2019)
🛠️ Tools:
- Mozilla TTS
- Coqui TTS
- ESPnet
- Google Cloud TTS
📖 Courses:
- Speech Processing (Coursera)
- Deep Learning for Audio (Fast.ai)
- TTS Systems (Udacity)
🎥 Resources:
- Google AI Blog
- OpenAI Research
- Papers with Code
Bạn muốn tích hợp Speech Synthesis vào sản phẩm?
📞 Hotline: 0947577892 (Zalo)
🌐 Website: hotrolaptrinh.com
💼 Email: khoilam.dev@gmail.com
Tạo trải nghiệm giọng nói tự nhiên với AI! 🎙️







